Translated Abstract
Improving the imbalance between supply and demand for nursery schools is an important issue in recent years. This paper aims to build a machine-learning model that estimates which nursery school each household will choose. We train the model, LightGBM, using (i) detailed information on the actual choice of nursery schools by each household collected through a Web questionnaire (conducted on 1,032 households across Japan) and (ii) attribute information of nursery schools all over Japan gathered from open data. The F-score for the trained model was 68.7%. Furthermore, based on the SHAP values calculated using the trained model, we demonstrate the quantitative impact of each explanatory variable (such as household attributes, facility characteristics, and commuting conditions) on the household nursery school choice.
1. はじめに
1.1 研究の背景
近年,核家族や共働き世帯の増加に伴い,保育所への入所を希望する世帯も増加傾向にある(厚生労働省,2021).こうした保育需要の増大に対応すべく,各自治体では,いわゆる待機児童対策として様々な規模・形態の保育所を新設している.こうした施策の効果や少子化によって,待機児童数は全国的に見ると減少傾向にあるとされている(こども家庭庁,2024).しかし,局所的には,0歳~5歳の子どもがいる世帯(以下,未就学児世帯)の入所希望が特定の保育所に集中し,希望する保育所に入所できない世帯が生じているケースが見られる(こども家庭庁,2024).また逆に,定員が充足されず,経営に苦しむ保育所も存在している(厚生労働省,2021).こうした保育所需給のミスマッチを根本的に改善する上で,未就学児世帯が入所を希望する保育所をどのような観点で選択しているかを分析することは重要である.
1.2 既往の関連研究
(1) 保育所の選択・入所実態の把握
これまでに多くの研究で,特定の地区の保育所やその利用世帯に対して調査票を配布・回収し,保育所の選択・入所実態の把握が試みられてきた.例えば浦ら(1958)は,団地と農村について地区ごとに保育所への通園状況を調査し,団地からは最短距離に立地する保育所が,農村では同一地区内に立地する保育所が,それぞれ選択されやすいことを示している.また,青木ら(1974)は,保育所・職場・居住地の3地点の距離関係,および,通園状況や世帯条件の情報を用いて,通園距離別の通園児数累積率で保育所を分類している.さらに,横山・伊藤(1965)は,保育所配置と保育児家庭の分布図を作成し,施設ごとに保育児の家庭の分布傾向や通園距離,通園所要時間,および時刻別の通園児率を調査している.こうした手法は,各世帯の保育所の選択状況を直接把握できるという長所を有するが,調査に多大な労力を要することから,広域で同様の調査を実施することは容易でなかった.
近年ではインターネット調査により,未就学児世帯の保育所選択要因について広く情報収集を行っている例も見られる.例えば河端(2010)は,未就学児世帯の保育所選択要因について詳細な集計結果を示し,考察している.しかし,各世帯がどのような理由で,どの保育所への入所を希望し,実際にどの保育所に通園しているかという具体的な情報は,プライバシーの観点から明らかになっていない.
(2) 施設選択
ある地域の利用者が複数の競合施設を選択する確率を推定する数理モデルとして,例えばハフモデル(Huff, 1963)や積乗型競合相互作用(MCI)モデル(Nakanishi and Cooper, 1974)が商圏分析などに活用されている.保育所の選択行動分析にMCIモデルを応用した例として,沖・増喜(2022)の研究が挙げられる.ここでは,自治体のホームページで公開されている保育所単位の定員や入所希望人数,および,施設の立地や基礎的な空間属性などの情報をもとに,100 mメッシュ単位で各保育所の選択確率を推定するとともに,シミュレーションにより地域の保育施策を評価している.しかし,世帯によって異なる属性や施設選択傾向は考慮できておらず,また,各施設の詳細な属性も十分に反映できていない.
1.3 研究の目的と構成
上記の背景をふまえ,本研究では,全国に居住する多数の未就学児世帯を対象として保育所の選択・入所実態を調査し,その結果をもとに,世帯単位で各保育所の選択・非選択を推定する機械学習モデル(以下,保育所選択モデル)を構築するとともに,世帯の属性や保育所の施設属性,通園条件などが世帯の保育所選択行動に及ぼす影響を定量的に把握することを目的とする.ひいては,社会的観点からは,世帯の需要と特性を考慮した施設整備・改善による保育所の需給ミスマッチの減少に,学術的観点からは,全国の世帯の保育所選択実態の把握,および,世帯や施設属性などの詳細な情報を考慮した施設選択モデルの有用性検証に貢献する.
本論文の構成を以下に示す.2章では,未就学児世帯が選択した保育所や実際の通園状況を把握することを目的として実施したWebアンケートの概要を述べる.3章では,Webアンケートの回答と,オープンデータから得た保育所施設情報に基づき,回答世帯ごとに,通園施設として選択する可能性がある保育所の集合(以下,保育所選択肢集合)を推定する方法を述べる.4章では,3章で作成した世帯ごとの保育所選択肢集合を学習データとして,保育所選択モデルを構築し,その精度を検証する.また,推定結果をもとに,各要因が世帯の保育所選択行動に及ぼす影響について分析・考察する.5章では,本論文のまとめと今後の展望を示す.
2. 保育所の選択と利用行動に関するWebアンケート
Webアンケートの概要を表1,実施画面の例を図1に示す.既往研究では多くの場合,特定の自治体に限定した調査を行っている.しかし,本研究では,保育所の需要と供給を取り巻く問題が日本全体で生じている現状をふまえ,全国の世帯を対象とした.そして,保育所への入所申請を行った世帯について幅広く回答を収集するため,子どもの長子・末子,実際の入所経験の有無に応じて設定したA~E群の世帯から回答を得た.このとき,あらかじめ設定した群ごとのサンプル数に達するまで調査を継続した(委託先の仕様により,調査票を配信したサンプル数は不明).また,調査時点で実際に通園している世帯だけでなく,指定期間に入所申請を行った世帯であれば,調査時点での通園状況や入所可否によらず回答対象とした.厚生労働省(2020)が公表している保育所等利用児童数・待機児童数と本アンケートの回答世帯数には強い正の相関関係が見られることから(図2),保育需要の分布に概ね対応した妥当な回答世帯分布になっていると言える.サンプル率の都道府県平均は0.036%であった.
表1 Webアンケートの概要


図1
Webアンケート実施画面の例
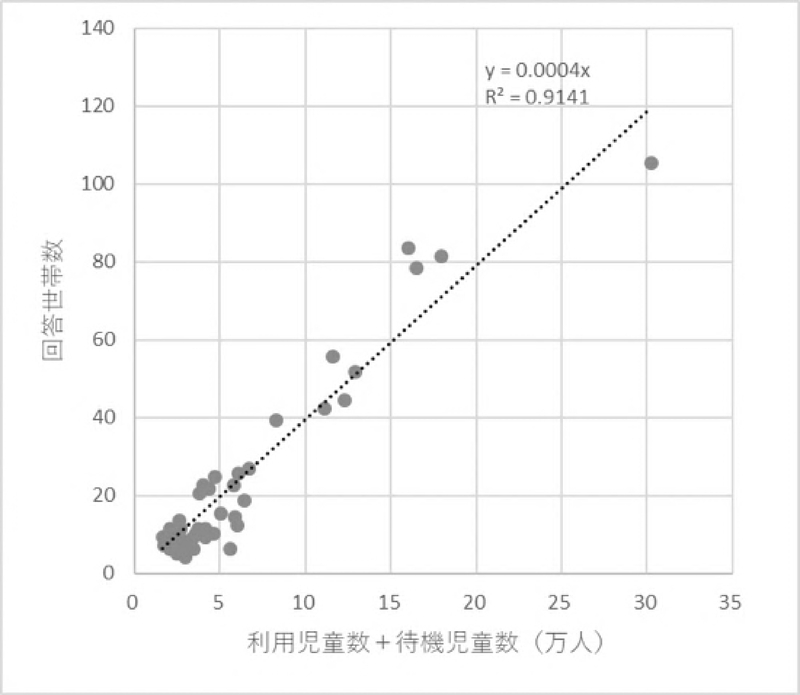
図2
保育所利用児童数・待機児童数の合計値とWebアンケートにおける回答世帯数の関係(都道府県別)
回答項目の一覧を表2に示す.本アンケートでは,未就学児世帯の保育所選択実態を具体的かつ段階的に把握するため,入所を希望していた保育所(第2希望まで:以下【希望1】【希望2】),自治体への入所申請書類に記入した保育所(第3希望まで:以下【申請1】【申請2】【申請3】),および,実際に入所できた保育所(以下,【実際】)について,それぞれの施設名称(Q5)や選択理由(Q6),想定交通手段(Q7),想定通園時間(Q8)を尋ねている点に特徴がある.また,実際の送迎行動に関する設問(Q11~Q14)や,回答世帯属性に関する設問(Q1~Q3,Q15~Q18)も設けている.居住地と勤務地/通学地(Q18)については,回答世帯のプライバシーに配慮しつつも,可能な限り詳細な位置情報を把握するため,自由記述形式で大字レベルまでの回答を求めた.ただし,市区町村レベルもしくは都道府県レベルの回答にとどまる世帯も一定数存在した.
表2 Webアンケートの回答項目

3. 世帯ごとの保育所選択肢集合の推定
3.1 目的
WebアンケートのQ5では,各世帯が【希望1】,【希望2】,【申請1】,【申請2】,【申請3】,【実際】の各段階で選択した保育所の施設名称を得た(のべ3,806施設).しかし,各世帯がそれぞれの保育所をなぜ選択したのかを把握するためには,Webアンケートで各世帯が選択した保育所だけに着目するのでなく,選択しなかった保育所との比較も必要である.
そこで本章では,施設選択モデルにおける距離抵抗の概念を参考に,「各世帯が入所希望の保育所を選択する際には,居住地周辺に立地する保育所のみが選択肢と成り得る」という仮定の下で,世帯ごとの保育所選択肢集合を推定する手法を構築する.
3.2 保育所選択肢集合の推定の流れ
保育所の施設情報は自治体の保育所入所申請資料やホームページ,あるいは施設個々のホームページなどから参照できるが,日本全国などの広範囲で網羅的にデータを収集することはこれまで困難であった.しかし,2020年から「ここdeサーチ」(福祉医療機構,2020)の運用・公開が始まったことで,日本全国の保育所の施設情報を網羅的,統一的,かつ簡便に取得することが可能となった.本研究でも,保育所選択肢集合推定において「ここdeサーチ」が重要な役割を果たす.具体的な推定の流れを以下に記す.
まず,Webアンケートの回答と「ここdeサーチ」に基づき,保育所ポイントデータを作成し,GISソフトを用いて地図上に保育所ポイントをプロットする(3.3節).次に,居住地が存在しうる空間範囲(以下,居住地領域)を回答世帯ごとに大字ポリゴンで代表させる(3.4節).そして,その各居住地領域の外周に,各世帯の通園手段と通園時間によって定まる幅のバッファを発生させ,「保育所選択領域ポリゴン」を作成した後,回答世帯ごとに保育所選択領域に含まれる保育所を空間結合により抽出することで,目的の「保育所選択肢集合」を推定する(3.5節).
3.3 保育所ポイントデータの作成方法
保育所ポイントデータの作成方法を図3に示す.

図3
保育所ポイントデータの作成方法
Webアンケートの回答に含まれる保育所については,世帯ごとに,【希望1】,【希望2】,【申請1】,【申請2】,【申請3】,【実際】の段階別に「居住地(Q18)and施設名称(Q5)」を検索クエリとしてGoogle Maps Geocoding APIに入力することで,保育所の位置座標を取得した.ただし,同一世帯が複数の段階で同一の保育所を記入している場合や,居住地が近接する異なる世帯が同一の保育所を記入している場合があることから,1つの保育所に対して1点が対応するように,こうした重複を削除した(1,702施設).次に,Webアンケートに含まれない施設の情報を補うことを目的として,「ここdeサーチ」に収録されている全ての保育所を対象に,「住所 and 施設名称」を検索クエリとして,Google Maps Geocoding APIで同様に位置座標を取得した(48,529施設).そして,Webアンケートをベースとした保育所ポイントデータと,「ここdeサーチ」をベースとした保育所ポイントデータを,施設名称の文字列に対して重複判定を行った上で統合した(図4).
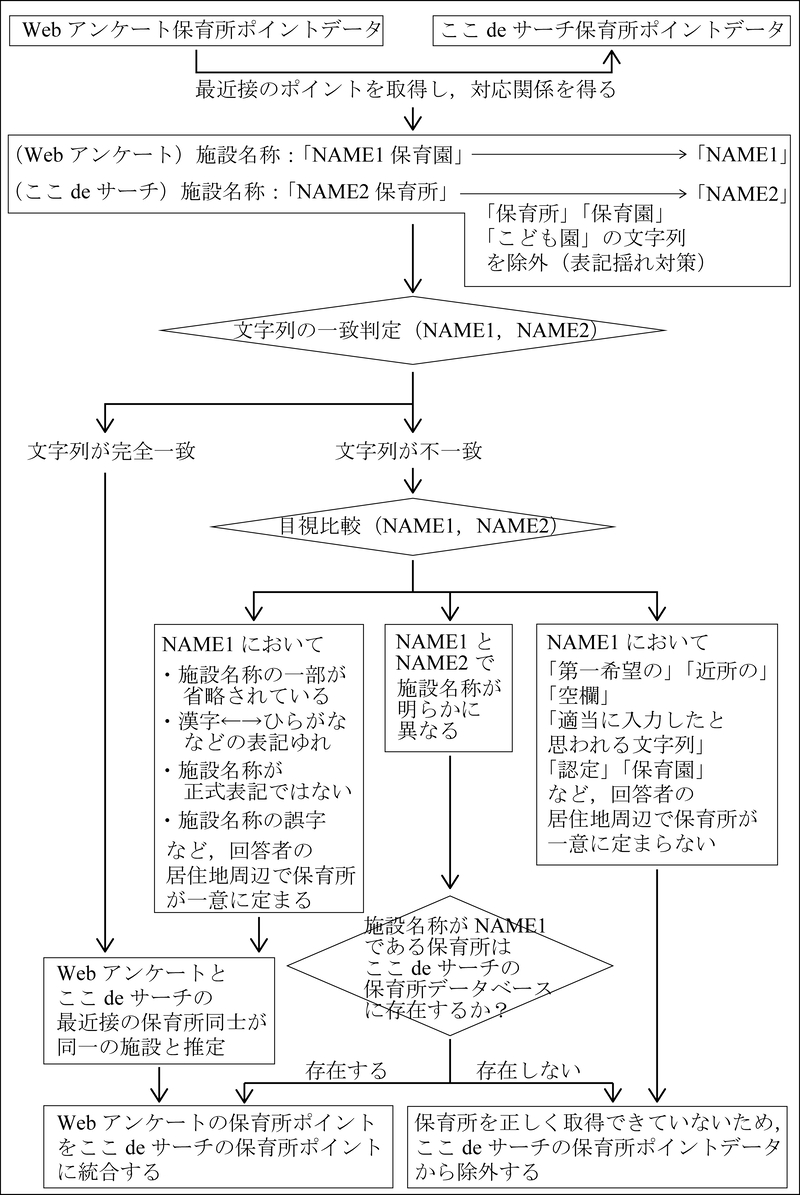
図4
保育所ポイントデータの重複判定
3.4 世帯の居住地大字ポリゴンの作成方法
前章で説明したWebアンケートでは,プライバシー保護の観点から,居住地の回答を大字レベルまでの自由記述式としている.そこで,各世帯の居住地を,居住地点が存在すると考えられる一定の範囲内(居住地領域)として扱う.また,居住地を市区町村レベルもしくは都道府県レベルまでしか回答していない世帯も存在する.そこで,居住地を大字レベルまで回答している世帯を以下の方法で抽出し,それらの居住地領域を推定した.
まず,Webアンケートで回答を得た全1,032世帯について,居住地の回答(Q18)に対して,CSVアドレスマッチングサービス(東京大学空間情報科学研究センター,〈https://yz-jsjc-gov-cn-1416.res.gxlib.org.cn:443/rwt/1416/https/M7TX8Z5QMSTT6Z5UNF3T67JNPSYXX8LQF3RXGLUKPA/〉)で住所階層を判定した.住所階層iLvl(図5(a))が5(大字)である(居住地の住所情報が大字レベルである)世帯は398世帯存在した.このうち,住所が正しいことを目視で確認できた357世帯について,Google Maps Geocoding APIに居住地の回答(Q18)を入力することで大字の代表点の座標を取得し,居住地ポイントデータを作成した(図6).さらに,居住地ポイントデータに大字境界データ(2020年国勢調査の小地域境界データ(総務省統計局,2020)を,大字単位でディゾルブしたもの)を結合させることで,各世帯の居住大字ポリゴンを得た(図5(b)).

図5
居住地に関するデータ処理
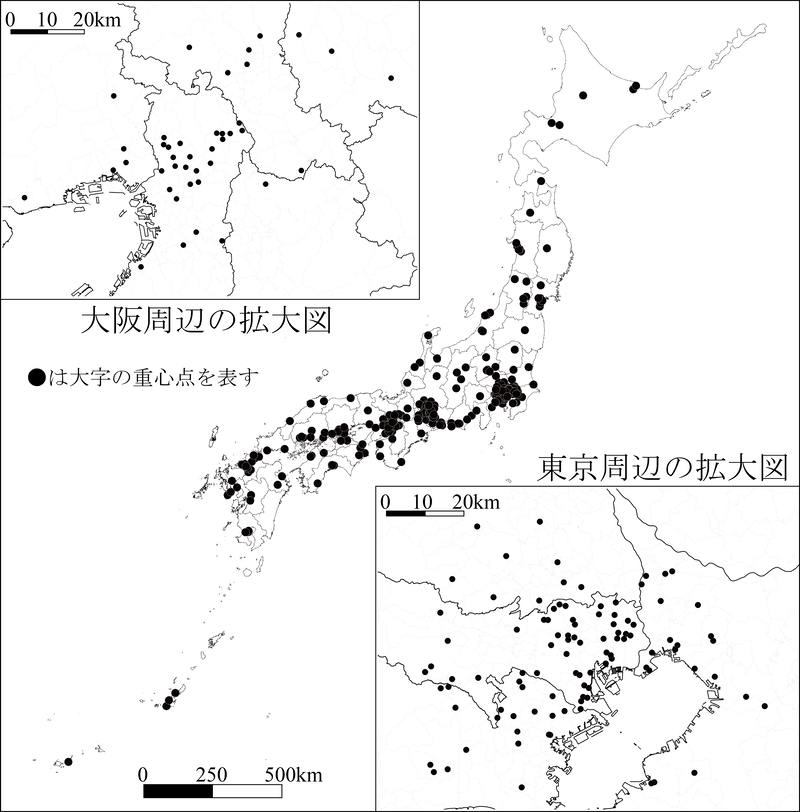
図6
居住地が大字まで判明した世帯の空間分布
3.5 保育所選択肢集合の抽出方法
保育所選択肢集合の抽出方法を図7に示す.
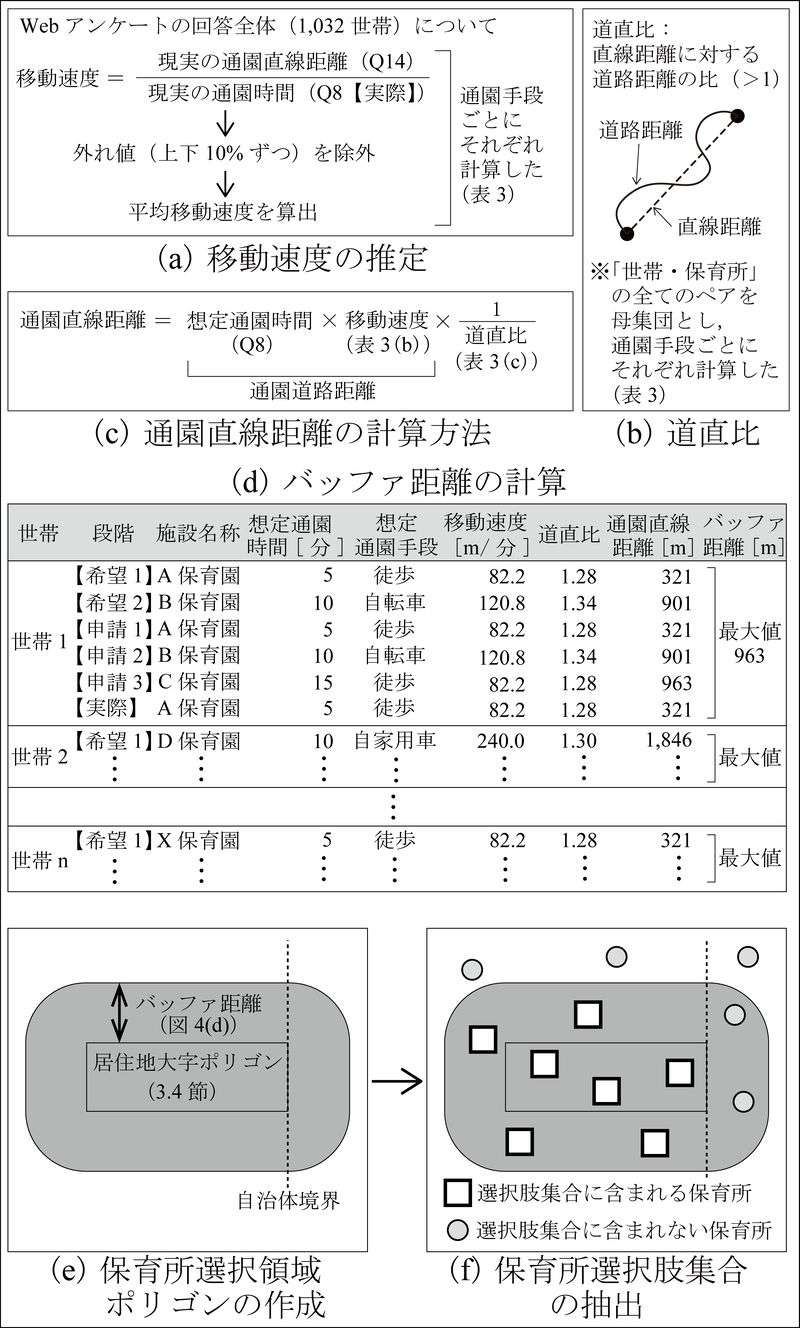
図7
保育所選択領域の推定方法
まず,Webアンケートの回答全体(1,032世帯)を母集団として,実際の通園時間(Q8【実際】)と直線距離(Q14)を集計して平均移動速度を(図7(a)・表3(b)),道路距離と直線距離(いずれもQ14)から道直比を(図7(b)・表3(c)),それぞれ想定される通園手段(Q7)ごとに得た.
表3 通園手段ごとの平均移動速度と道直比
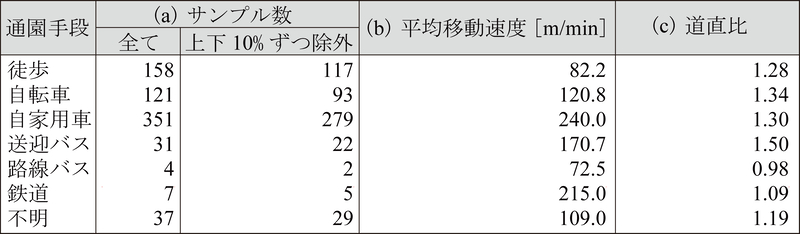
次に,各世帯が【希望1】,【希望2】,【申請1】,【申請2】,【申請3】,【実際】の各段階で選択した各保育所との間の想定通園時間(Q8)に,上述の平均移動速度を乗じ,さらに道直比で除すことで,それぞれの施設までの通園直線距離を推定した(図7(c)).実際に通園していない施設までの直線距離を回答することは,想定される通園時間を回答することよりも難しいと考え,このような推定方法を採用した.そして,推定した通園直線距離のうちの最大値を世帯ごとの「バッファ距離」とし(図7(d)),その幅のバッファを,当該世帯の居住大字ポリゴン(3.4節)の周囲に生成した.生成したバッファポリゴンと居住大字ポリゴンの和集合を「保育所選択領域ポリゴン」と呼ぶ(図7(e)).
実際には,認可保育所については自治体ごとに申請が行われていることを考慮して,3.3節で作成した保育所ポイントデータに含まれる保育所のうち,各世帯の保育所選択領域ポリゴンの内部に含まれ,かつ,施設の立地する自治体が世帯の居住地と一致するもの(のべ10,569施設)を,当該世帯の「保育所選択肢集合」として抽出した(図7(f),図8).ここで抽出された「世帯・保育所」のペアを1サンプルとして数えると,前節で居住地領域ポリゴンを得た357世帯から,計10,506サンプルの世帯・保育所ペアが得られた(平均29.4施設/世帯).
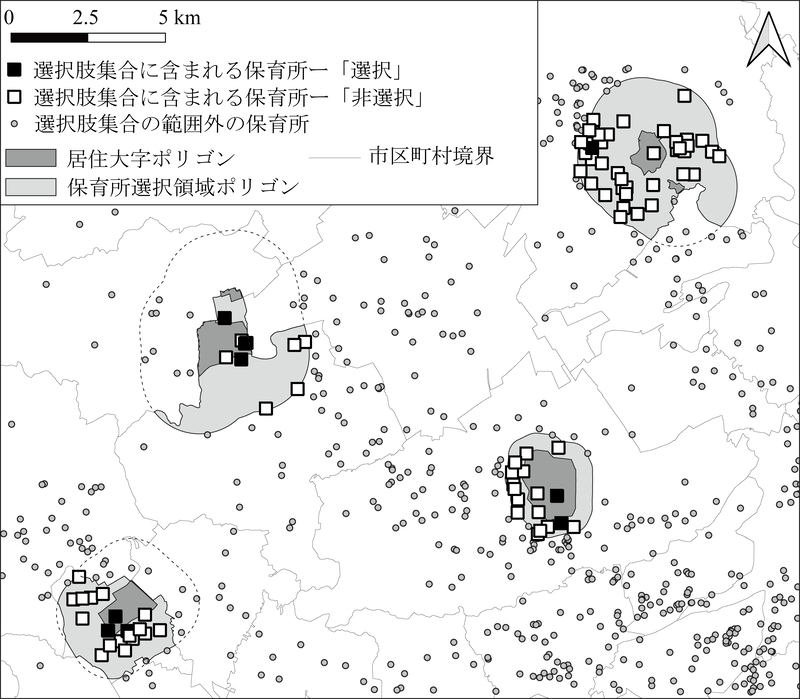
図8
保育所選択領域と保育所選択肢集合の例
4. 世帯単位の保育所選択モデル
4.1 保育所選択モデルの概要
前章で推定した回答世帯ごとの保育所選択肢集合に含まれる保育所のうち,Webアンケートにおいて【希望1】,【希望2】,【申請1】,【申請2】,【申請3】,【実際】のいずれかの回答に含まれる施設に「選択」,いずれの回答にも含まれない施設に「非選択」のラベルを付与した(図8).この2クラスのラベルを目的変数,「ここdeサーチ」の施設情報から抽出した保育所属性,および,Webアンケートの結果から抽出した世帯属性を説明変数として,各世帯による保育所の選択・非選択を推定する判別モデル(保育所選択モデル)を構築した.
4.2 保育所選択モデルの説明変数
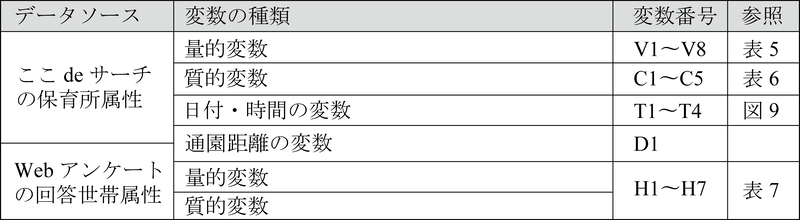
保育所選択モデルに用いる説明変数は,表4のように分類できる.
表4 保育所選択モデルの説明変数の一覧
-
(1)
保育所属性:量的変数として,定員や最寄駅までの距離,周辺の保育所数など,表5に示す変数を採用した.質的変数には,法人等の種類や施設類型等を含み,類似する項目を集約した上でカテゴリ変数に変換した(表6).保育所の事業開始年月日については,「ここdeサーチ」のデータの取得日(2022年3月1日)までの経過月数を連続変数とした.保育所の開所時刻・閉所時刻については,開所から閉所までの時間長さ,および,開所・閉所の基準時刻(それぞれ7時・19時)との差分を分単位で算出することで,同様に連続変数として扱った.すなわち,当該施設の開所(閉所)時刻が開所(閉所)の基準時刻より遅い場合には,負の値をとる(図9).
表5 保育所属性に関する量的変数の一覧
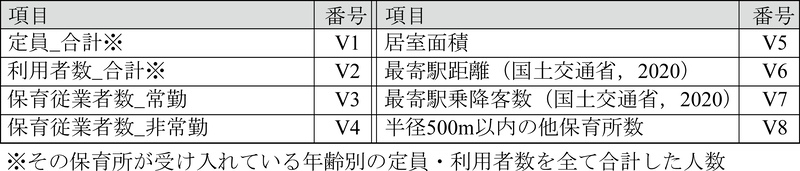
表6 保育所属性に関する質的変数の一覧
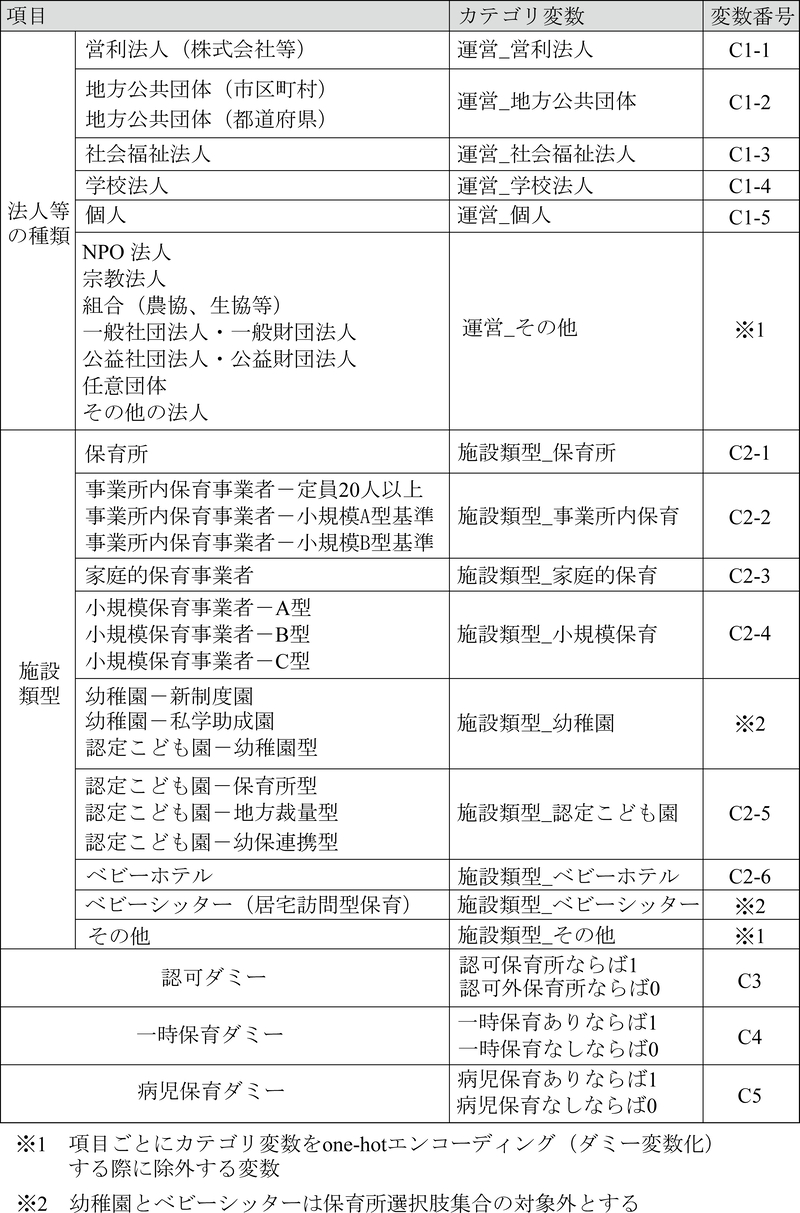
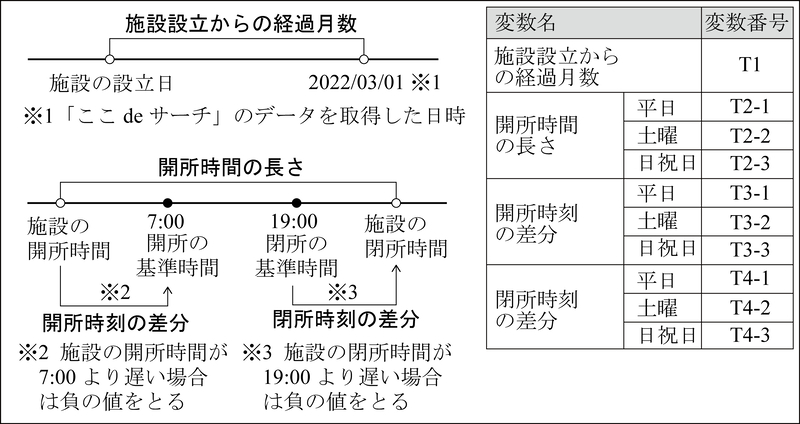
図9
日時に関する連続変数の取得方法
-
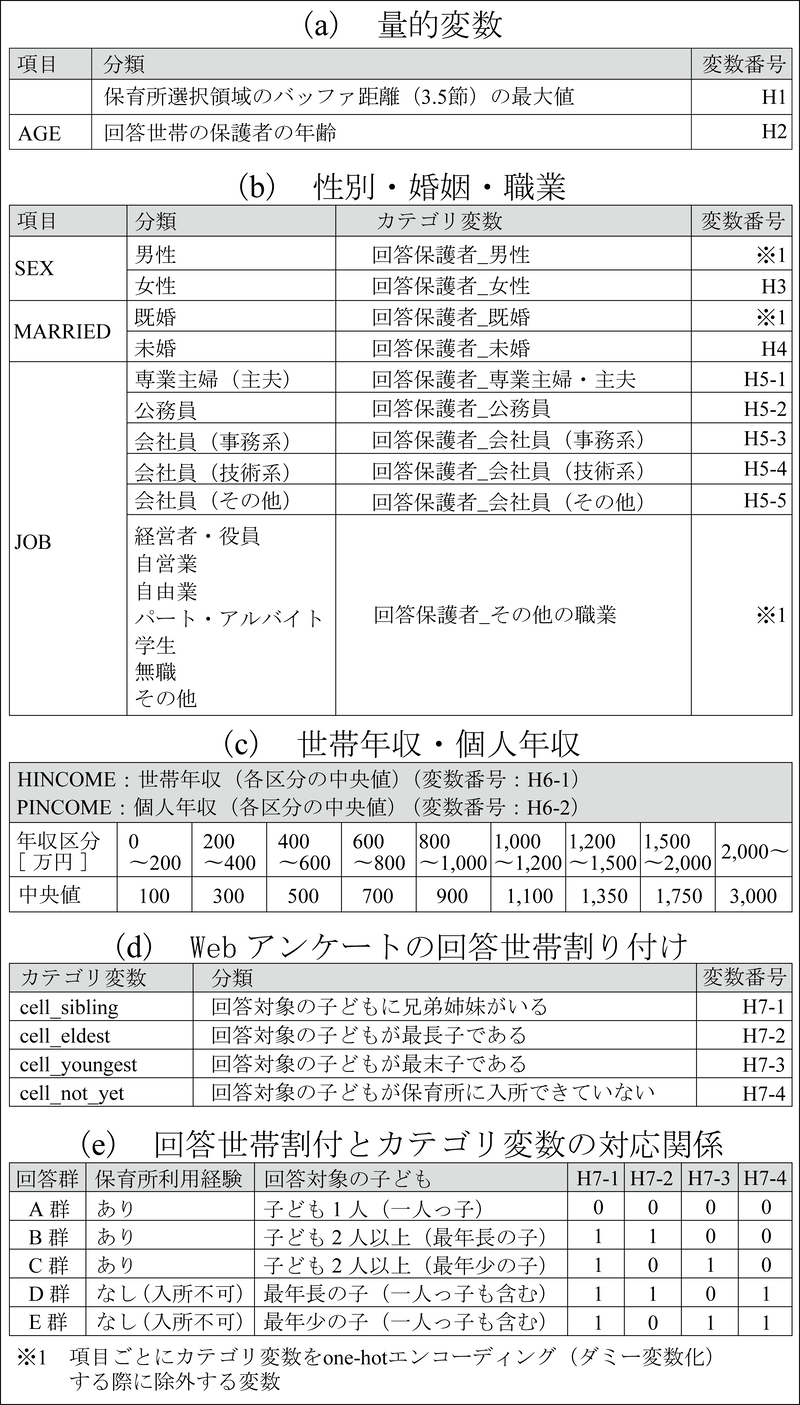
(2)世帯属性:保護者の性別・未既婚・職業はカテゴリ変数に変換し(表7(b)),世帯年収・個人年収については収入額帯ごとの中央値で代用して量的変数と見なした(表7(c)).さらに,兄弟姉妹の有無や長子・末子の区別に対応するカテゴリ変数を作成し(表7(d)),Webアンケート実施時の回答の割付状況と対応させた(表7(e)).
表7 世帯属性に関する変数
-
(3)その他:世帯の居住大字ポリゴン(3.4節)の重心点から保育所選択肢集合に含まれる各保育所までの直線距離(擬似通園距離)を説明変数に含めた.
前節で述べたように,本研究では多数の説明変数を用いることから,目的変数(各世帯の保育所の選択・非選択)の間に線形関係が成立するとは限らない.また,主に「ここdeサーチ」に由来する施設属性に関する説明変数には欠損値が散見された.そこで本研究では,決定木を多数用いて多数決により予測を行うアンサンブル学習により,非線形関係と説明可能性を考慮し汎化性能を向上したLightGBM(Ke et al., 2017)を,保育所選択モデルの構築に採用した.
LightGBMは決定木アルゴリズムに基づいた勾配ブースティングのフレームワークであり,教師あり機械学習の手法の1つである.決定木の構築にLeaf-wise成長戦略を使用しており,Level-wise成長戦略と比較して予測精度が高い一方,過学習しやすく,適切な正則化処理を要する.また,決定木をヒストグラムに基づいて作成するなどメモリ使用量軽減の工夫がなされており,大規模データセットに対しても効率的な学習が可能であるほか,説明変数に欠損値を含む場合でも学習と予測が可能な点も長所といえる.
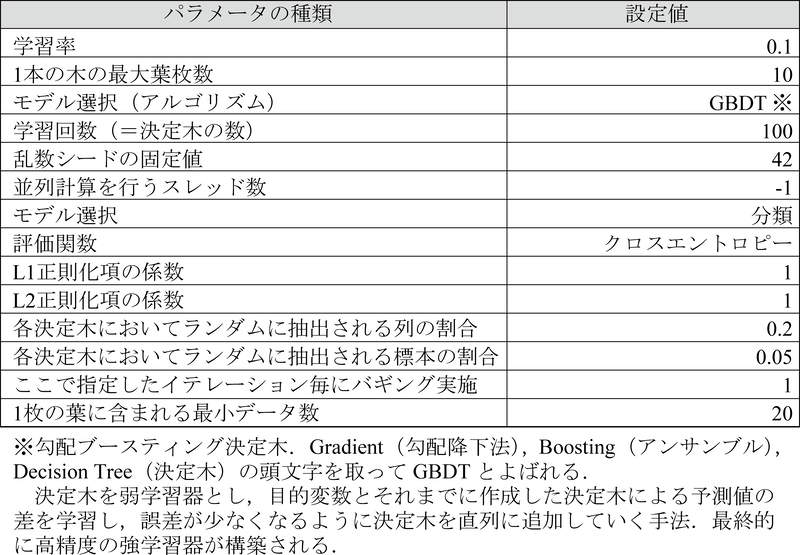
学習データには保育所選択肢集合に含まれる世帯・保育所ペアの合計10,506サンプル(3.5節)を用いる.ただし,「選択」ラベルが付与されたものが837サンプルであるのに対し,「非選択」ラベルが付与されたものが9,669サンプルと,2クラスのサンプル数に大きな偏りが見られた.そこで,アンダーサンプリングにより「選択」と「非選択」をともに837サンプルに揃えた(表8).「非選択」クラスのアンダーサンプリングの際,認可保育所とそれ以外の保育所のサンプル数が「選択」クラスにおける内訳と等しくなるよう,それぞれ816サンプルと21サンプルをランダムに抽出した.そして,「選択」クラスと「非選択」クラスを合わせた計1,674サンプルを学習データとし,5分割交差検証(5-Fold Cross-Validation)によりモデルの学習を行った.このとき,各説明変数の値は,平均0,標準偏差1となるように標準化してある.また,訓練(Train)データとテスト(Test)データの予測精度に大きな差が生じないようにハイパーパラメータの値を調整した(表9).
表8 LightGBMの学習データのサンプル数

表9 LightGBMのハイパーパラメータ
4.4 保育所選択モデルの予測結果
5分割交差検証の結果,テストデータのF値が最も大きい「最良モデル」の混同行列と精度評価指標を表10(a)に示す.具体的には,正解率(Accuracy)は0.658,F値は0.687であった.「非選択」の保育所を「選択」と推定する傾向がやや強く,再現率(Recall)に比べて適合率(Precision)が低くなっている.
表10 保育所選択モデルの予測精度
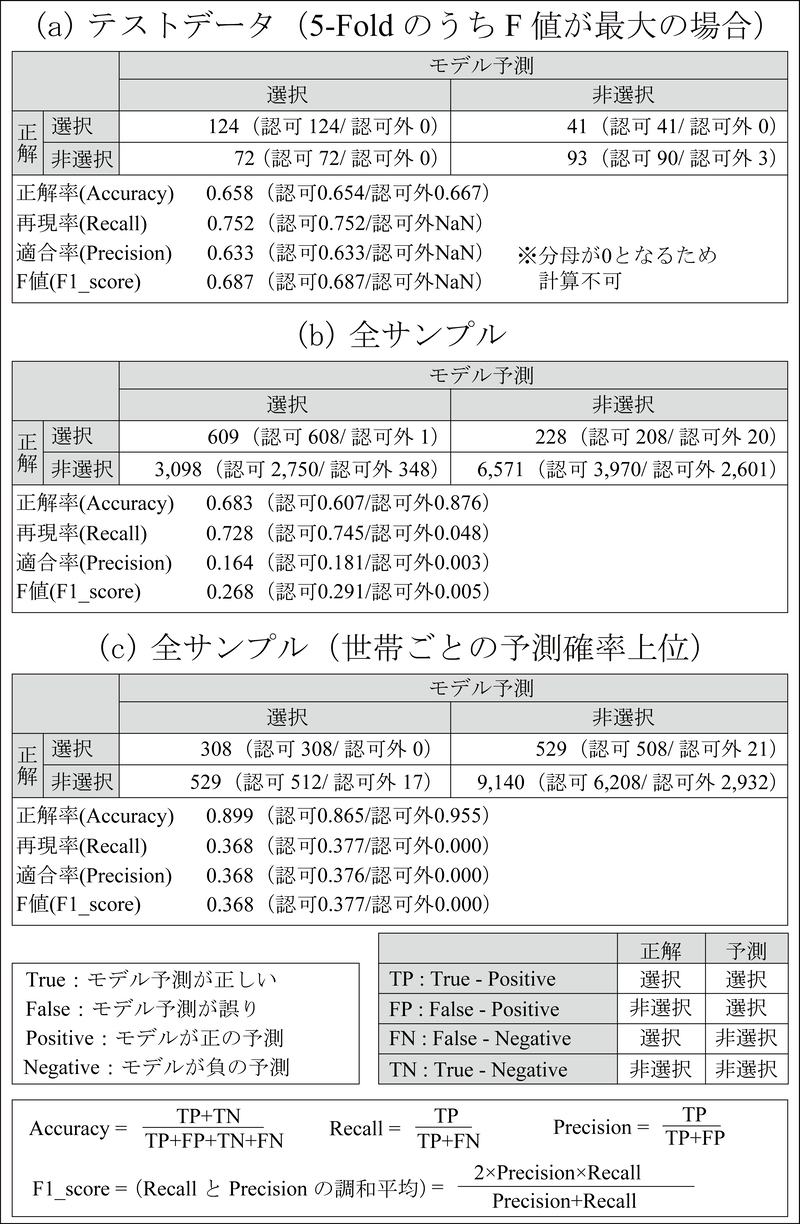
この最良モデルを全ての世帯・保育所ペア(計10,506サンプル)に適用し,選択・非選択の推定を試みた結果を表10(b)に示す.正解率や再現率はテストデータの結果(表10(a))と同程度であるが,適合率が低い傾向がさらに顕著となっている.この理由として,①保育所選択肢集合に含まれる保育所数の多さ(平均29.4施設/世帯,3.5節)に対して,正解が「選択」である施設数が少ないこと(最大6施設)や,②保育所選択モデルは全国からサンプリングした世帯・保育所ペアを学習させていることから,選択されやすい特徴をもつ施設が都市部などで集中して立地している場合,多くの施設が「選択」と推定される傾向があることなどが挙げられる.
そこで,保育所選択モデルが出力する選択確率(Sigmoid関数により0~1の連続値で出力され,その値をもとに,0.5以上の場合に「選択」,0.5未満を「非選択」として二値化している)に基づく別の推定手法を検討した.具体的には,世帯ごとに,保育所選択肢集合に含まれる施設を選択確率の高い順にソートし,その上位から実際に選択した施設数と同じ数の施設を「選択」,それ以外を「非選択」と推定することを試みた.その結果,正解率は約9割に達し,適合率には改善が見られたが,実際の「選択」施設を「非選択」と推定するケースが増加し,再現率が悪化した(表10(c)).より精度の高い推定方法の検討が今後の課題である.
4.5 SHAPによる要因分析
最良モデルをテストデータに適用した結果(表10(a))に対し,SHAP(SHapley Additive exPlanations:Lundberg and Lee, 2017)を導入し,保育所選択モデルによる選択・非選択の推定に,各説明変数がどの程度影響しているかを分析した.SHAP値は,協力ゲーム理論においてプレイヤーの限界貢献度から算出されるシャープレイ値を,説明変数による予測結果への寄与度の定量化に応用した指標である.
推定への寄与度が大きい説明変数について,説明変数とSHAP値それぞれの大小関係を図10に示す.
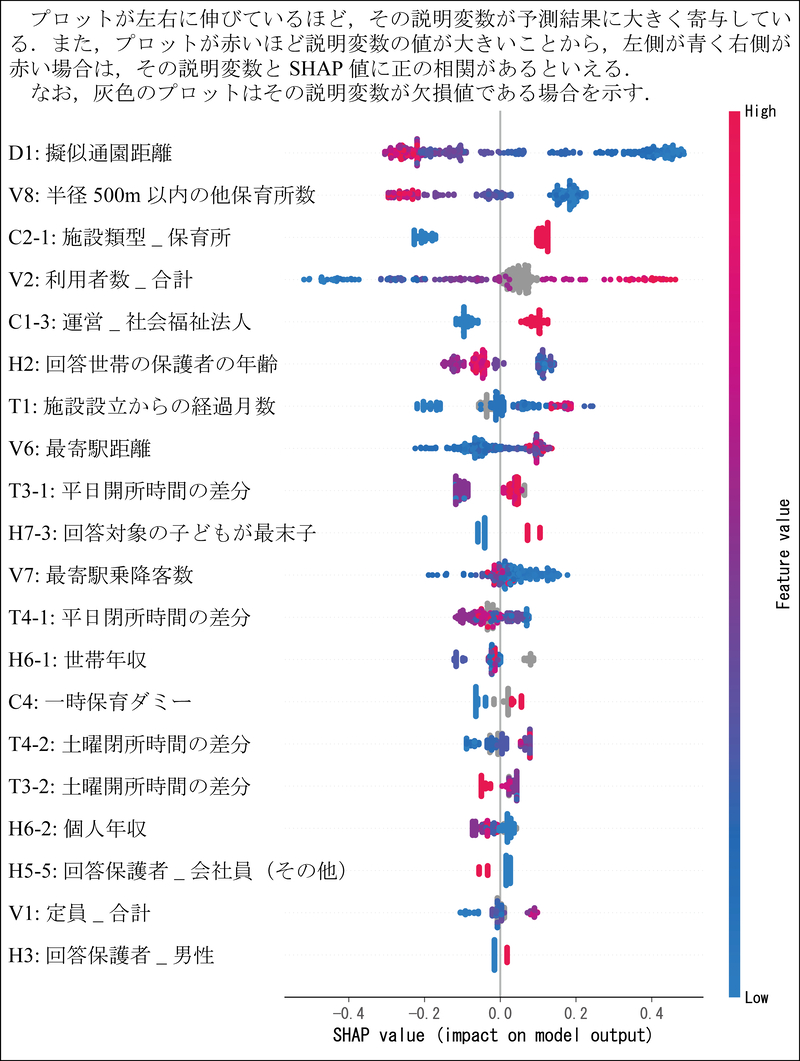
図10
説明変数ごとのSHAP値プロット
例えば,擬似通園距離(D1),半径500 m以内の他保育所数(V8),利用者数_合計(V2)などの寄与度が大きいことがわかる.特に擬似通園距離については,SHAP値が広く分布しており,かつ,特徴量の値(Feature value)が小さい(大きい)サンプルほど,SHAP値が正(負)に大きい位置に分布する傾向が明確に確認できる.これは,擬似通園距離が短いほど「選択」傾向が見られ,通園利便性が世帯の保育所選択に強く影響することを表している.また,施設利用者数が多いほど「選択」傾向にあるが,この傾向は施設定員(V1)よりも強く,実際に多数の未就学児を受け入れている保育所が好まれる傾向が見てとれる.開所閉所時間については土曜(T3-2)よりも平日(T3-1)の方がやや強く影響しており,平日のみ働いている保護者の影響と考えられる.世帯属性の観点では,回答保護者の年齢(H2)が若い場合や,子どもが最末子である場合(H7-3)には,各施設の「選択」傾向がより高まる可能性が見てとれる.
5. まとめ
5.1 結論
本論文では,保育所入所申請を経験した子育て世帯を対象としたWebアンケートの回答結果と,保育所オープンデータベース「ここdeサーチ」から入手した日本全国の保育所の施設情報を活用して,世帯単位で保育所選択肢集合を推定し,世帯ごとの保育所選択を推定する機械学習モデル(保育所選択モデル)を構築した.
5.2 今後の課題
-
(1)
本論文では,保育所選択モデルの学習の際,「選択」サンプル数と「非選択」サンプル数の学習データにおける偏りを考慮し,アンダーサンプリングにより「非選択」サンプル数を削減する処理を行った(4.3節).その結果,アンダーサンプリングを行わない場合と比較して,推定精度が向上することを別途確認している.しかし,アンダーサンプリングによるデータ削減が,モデルの性能やデータ分布に影響を及ぼし,結果にバイアスを生じさせている可能性が考えられる.バイアスを緩和させるための方法としては,①性別・年代・居住地域といったサブグループごとに,均等な割合でアンダーサンプリングを実施し,特定の層が極端に減らないようにする方法(分層アンダーサンプリング),②「非選択」サンプルを削減する代わりに,何らかの方法で「選択」サンプルの合成データを生成することで情報を補完する方法(データ拡張),③明らかに「非選択」とされるサンプルなど,モデルの学習に影響の少ないサンプルを優先的に削減し,バランスを保つ方法(適応的アンダーサンプリング)などが考えられる.これらの方法を採用した場合との結果の比較が課題である.
-
(2)
第2章で実施したWebアンケート調査では,日本全国の世帯を対象としたが,地域別の施設選択傾向の違いに着目した分析には至っていない.また,地域による施設の分布傾向や選択傾向の違いが,モデルの精度に影響を及ぼしている可能性がある.地域を考慮した分析手法への拡張が課題である.
-
(3)
交通手段によって通園時の身体的負担が異なることから,保育所選択肢集合の広さや形状にも影響を及ぼしうる.Webアンケート調査(表2)のQ4では,理想的な通園時間と許容できる通園時間の上限を交通手段別に尋ねており,この結果を交通手段別の保育所選択傾向の分析などに活用できる可能性がある.
今後は,本論文で構築した世帯単位の保育所選択モデル,および,Webアンケートの詳細な回答情報を,保育施策の評価・検討等に応用する予定である.自治体にとっては,世帯単位の保育所選択モデルに基づく地域の保育所入所シミュレーションにより,保育所の需給バランスに関する空間的問題点を明確化できる.さらに,保育所のどの施設属性が,世帯の施設選択行動にどの程度影響しているかが明らかになることで,従来よりも具体的かつ効果的な保育施策を検討・施行可能となることが期待される.後者は保育所にとっても重要であり,自施設のどの属性をどのように変化させれば,自施設の入所希望者数を増やせるかの検討に役立つ.特に,入所希望者数が定員に満たず,施設経営に課題を抱える保育所には有効である.こうして,自治体主導での保育施策の施行や,各保育所の努力による施設の改善が図られることで,保育サービスの質が全体的に向上すれば,保育所利用(希望)世帯の満足度向上につながることも期待される.
謝辞
本研究において使用したWebアンケートの回答にご協力いただいた方々に深く感謝申し上げます.
本研究は,JST科学技術イノベーション創出に向けた大学フェローシップ創設事業JPMJFS2112の支援を受けたものです.また,東京大学CSIS共同研究No.1041の一環として実施しました.
参考文献
- 青木正夫・河野泰治・竹下輝和・松下隆太(1974)保育施設に関する研究−施設の利用型について−.「日本建築学会大会学術講演梗概集(北陸)」,49,701-702.
- 浦良一・日下あこ・柳沢忠・土肥博至(1958)小見川町と都内団地の保育施設利用.「日本建築學會関東支部研究報告」,44,193-196.
- 沖拓弥・増喜浩太郎(2022)保育所選択行動モデルの構築と地域保育施設計画評価への応用.「日本建築学会計画系論文集」,87,802,2480-2491.
- 河端瑞貴(2010)仕事と子育ての両立とアクセシビリティーに関するアンケート調査報告書.「CSIS Discussion Paper」,102,1-39.
- 厚生労働省(2020)保育所等関連状況取りまとめ(令和2年4月1日).〈https://yz-jsjc-gov-cn-1416.res.gxlib.org.cn:443/rwt/1416/https/P7RYE6BPMSRT65UENRYGP53PNJZA/info:ndljp/pid/12862028/www.mhlw.go.jp/stf/newpage_13237.html〉
- 厚生労働省(2021)保育を取り巻く状況について(令和3年5月26日).〈https://yz-jsjc-gov-cn-1416.res.gxlib.org.cn:443/rwt/1416/https/P75YPLUNNBXHPLUHN6YGV6A/content/11907000/000784219.pdf〉
- こども家庭庁(2024)保育所等関連状況取りまとめ(令和6年4月1日)及び「新子育て安心プラン」集計結果.〈https://yz-jsjc-gov-cn-1416.res.gxlib.org.cn:443/rwt/1416/https/P75YPLUDM3RT635QF3WHA/policies/hoiku/torimatome/r6/〉
- 国土交通省(2020)国土数値情報(駅別乗降客数データ).〈https://yz-jsjc-gov-cn-1416.res.gxlib.org.cn:443/rwt/1416/https/N3XGM7DRF3XXZ4LVF3UX8LUKPA/ksj/gml/datalist/KsjTmplt-S12-v2_3.html〉.
- 総務省統計局(2020)政府統計の総合窓口(e-Stat)令和2年国勢調査 町丁・字等境界データ.〈https://yz-jsjc-gov-cn-1416.res.gxlib.org.cn:443/rwt/1416/https/P75YPLUFFW3YIZLVF3UX8LUKPA/〉
- 独立行政法人 福祉医療機構(2020)ここdeサーチ.〈https://yz-jsjc-gov-cn-1416.res.gxlib.org.cn:443/rwt/1416/https/P75YPLUYMFXT635QF3WHA/kokodesearch/ANN010100E00.do〉
- 横山敬雄・伊藤綸子(1965)札幌市における保育所の現状とその問題点−2.施設配置とその利用の面から−.「日本建築学会北海道支部研究発表会報告」,25,49-52.
- D. L. Huff (1963) A Probabilistic Analysis of Consumer Spatial Behavior. University of California.
- G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T. Liu. (2017) LightGBM: a highly efficient gradient boosting decision tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), 3149-3157.
- Lundberg, S. M., & Lee, S.-I. (2017) A Unified Approach to Interpreting Model Predictions. Advances in Neural Information Processing Systems, 30, 4765-4774.
- M. Nakanishi and L. G. Cooper (1974) Parameter Estimation for a Multiplicative Competitive Interaction Model. Journal of Marketing Research, 303-311. 〈https://yz-jsjc-gov-cn-1416.res.gxlib.org.cn:443/rwt/1416/https/MSYXTLUQPJUB/10.2307/3151146〉
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/33_24_t1.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/33_24_t2.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/33_24_t3.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/33_24_t4.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/33_24_t5.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/33_24_t6.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/33_24_t7.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/33_24_t8.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/33_24_t9.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/33_24_t10.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)